




Global leadership: Our MLPerf Training & Power V4.0 results
MLPerf® Training V4.0
Performance with efficiency: Energy use & our results
Our mission is simple: to convert electrons into knowledge as efficiently as possible. We believe transparency - of all AI's cost inputs - is the only way to move the industry towards genuine efficiency.





The benchmark
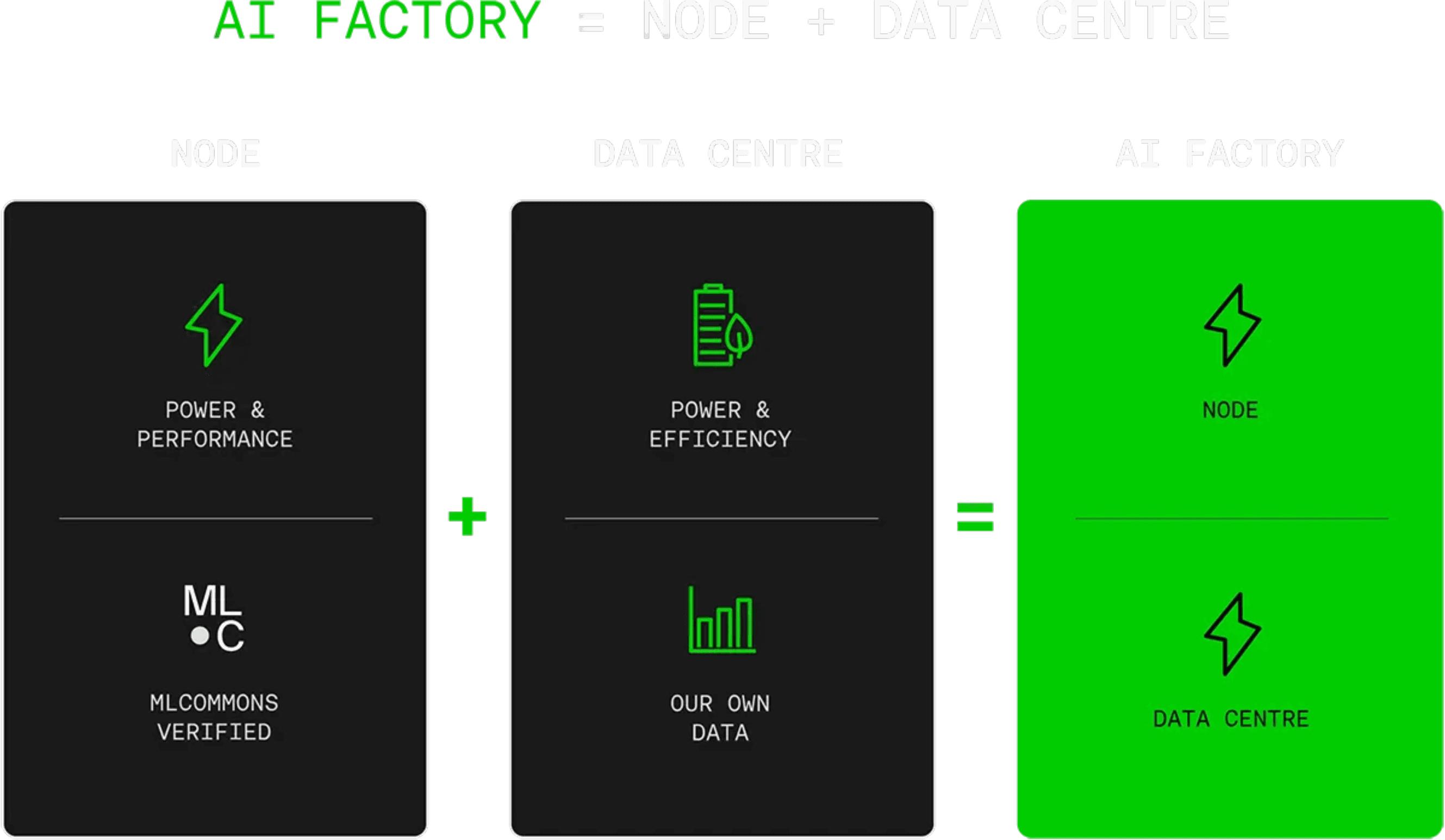
For each MLPerf® training result, we measured the power consumption of each 'node' or GPU server.
For each MLPerf® training result, we measured the power consumption of each 'node' or GPU server. This was captured as far upstream as possible - at the level of our immersion-rack power shelves - to accurately assess each node's power consumption. This portion of our MLPerf® submission was reviewed and verified by MLCommons and other members. At this level, our results show approximately 30% better performance compared to H100 SXM-based systems cooled with air, the most common method for building GPU clusters today.
However, capturing power at the node is only part of the story. The host data center plays an incredibly important role in measuring the energy efficiency of an AI Factory. Data center power usage was not within the scope of this round of MLPerf®, but we hope it will be included in future evaluations. Measured by PUE (Power Usage Effectiveness), our data center level provides a (non-MLCommons-verified) estimate of the total power required for the relevant test - end to end.
View our results