




Bare Metal
Dedicated GPU clusters with InfiniBand networking for uncompromising AI performance at scale.
Solutions
Dedicated infrastructure for demanding AI workloads
Purpose-built bare metal clusters that deliver control and scalability for AI training, inference, and high-performance computing.
Train LLMs
Bare metal clusters with multi-GPU nodes and low-latency InfiniBand for distributed model training.
Run Agentic AI
Deploy agent workflows at scale with full access to GPU resources and NIM APIs.
Enterprise ML Operations
Operate secure production ML pipelines with predictable performance and full observability.
High-Performance Computing
Drive large-scale simulations and CUDA workloads with dedicated access to GPU hardware.
Cluster Specs
From reserved single-tenant nodes to multi-rack GPU clusters, Firmus Bare Metal scales with your workload.
Best for training mid-to-large scale LLMs

4×–8× NVIDIA H200 GPUs

InfiniBand + GigabitEthernet

Configurable GPU and system RAM

High-throughput RDMA and RoCEv2-capable storage
Start training, testing, or deploying today with Firmus AI Cloud.
Optimized for control
Reserved clusters, unshared performance, and secure connectivity
With Slurm orchestration, observability, and hybrid cloud support, Firmus Bare Metal puts you in full control of training and inference.
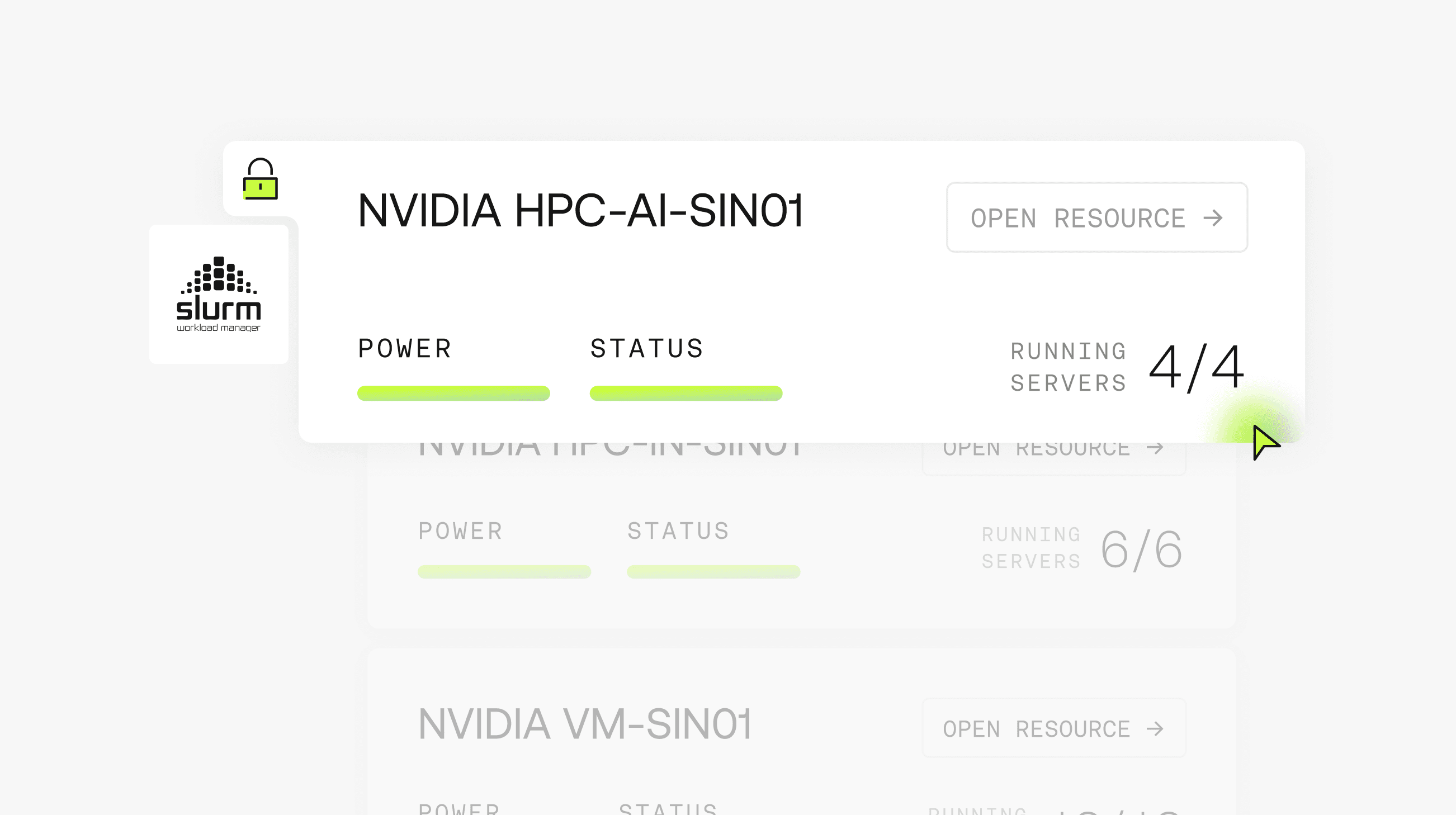
Availability
Dedicated GPU clusters available by reservation
Layer onto your workflow
AI WORKBENCH
High-performance: on-demand or reserved instances for AI workloads.
NIM INFERENCE APIs
Deploy AI development environments instantly with NVIDIA NIM.
OBSERVABILITY & MONITORING
Track GPU usage, job performance, and costs with built-in observability tools.